The credibility of scientific inquiry depends on researchers’ ability to replicate previous findings. However, publication biases that favor statistically significant results reward research practices that undermine replicability and increase the probability of false positives (Simmons et al., 2011). In the wake of recent failures to verify published research findings, research communities are increasingly pushing for the adoption of transparent and reproducible research paradigms.
Current frameworks to address the “replication crisis” have focused on randomized experiments. However, many important social science findings come from the analyses of observational data—data the world has already produced—like election outcomes, incidents of war, and legislative votes. As such, it is important to also develop a framework to increase our confidence in the reliability of the knowledge generated from observational studies.
Lacking new data, the tools for probing the robustness of observational findings often amounts to (1) making modifications to the original empirical strategy and/or (2) introducing new cases or topics of study in which a similar pattern should theoretically emerge. These practices have their place. However, as strategies for assessing a past finding’s validity, both practices suffer from a pathology that replication is meant to prevent. In particular, given a wide range of possible alternative cases and specifications, researchers may engage in “null hacking,” doing a search for specifications and/or cases that produce null results (Protzko, 2018).
Discussions of replicability usually focus on how the search for novel results can motivate “p-hacking,” or seeking out cases and/or specifications that produce p-values less than 0.05. Presumably, this occurs because researchers believe journals favor statistically significant findings (Franco et al., 2014). For replication studies, however, the incentive cuts in the opposite direction: if the researcher believes that replication studies are more likely to be published if they challenge rather than confirm existing findings, an incentive exists to produce a null finding (Galiani et al., 2017).
In light of these issues, we propose a five-feature approach for determining the reliability of results from observational studies, which we refer to as an observational open science (OOS) approach.
First, conduct multiple simultaneous replications of distinct studies testing the same theoretical claim. Conducting simultaneous replications provides an opportunity to root separate but related studies in a common identification strategy. Multiple simultaneous replications also help address sampling variability: any given false positive could survive, but it is unlikely that every false positive would survive. Moreover, if some findings are more robust to replication efforts than others, the research community gets an opportunity to determine whether there is a theoretical reason why.
Second, collect all data independently instead of using the original studies’ replication dataset. Observational studies often require several coding and data merging steps, and each step invites the possibility of error. Replication approaches that rely on the original study’s already-collected data forego the opportunity to identify data cleaning, coding, and merging problems that could have driven the original results. Moreover, there could be corrections to the raw data itself that were not available to the original authors.
Third, leverage the passage of time to extend the time series without changing the original study’s underlying units of analysis. This allows one to add new data to tests of original findings while still analyzing the same phenomenon. This is the observational analogue to replicating an experimental protocol with a new sample.
Fourth, pre-register all analyses. Preregistering replications of observational studies helps assuage concerns about “null hacking,” and encourages replicating authors to carefully consider the theoretical and empirical justification for analytical modifications before knowing the results. Agreeing on an optimal empirical strategy can be difficult, but proposed alternatives like examining all possible specifications risk pushing theory into the background.
Fifth, build a team that is a collaboration between authors with mixed incentives—some authors with a stake in the original results and others with no such stake (and potentially a motivation to overturn the original findings). “Adversarial collaborations” can make pre-registered replications more credible, as both the original and new authors must agree a priori on the parameters of the re-analysis prior to seeing the results, and can hold each other accountable to the pre-registered plan.
Some aspects of our OOS approach, especially pre-registration, have been advanced elsewhere as ways to improve the quality of research. The novelty of our approach is in bringing together multiple features, some of which we think are under-emphasized, and in demonstrating how they can advance the transparency of replicating observational research by applying our approach to a related set of papers researching an important topic in political science research: irrelevant events and voting behavior.
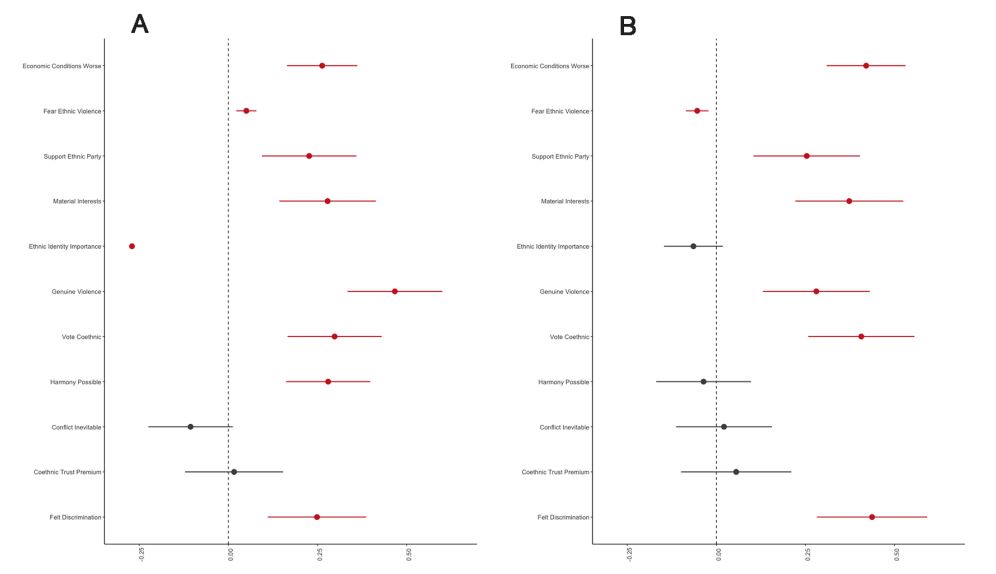
The empirical literature on irrelevant events and voting behavior is characterized by confusing and conflicting findings, which made it a good candidate for testing our OOS approach. We applied each of the five features in a replication exercise of three prominent studies on “irrelevant” events and voting behavior: (1) Achen and Bartels’s (2016) study of droughts and floods; (2) Healy, Malhotra, and Mo’s (2010) study of college football; and (3) Healy and Malhotra’s (2010) study of tornadoes.
We find that while the original findings successfully replicated in many instances, some findings did not. For instance, the main effects of the droughts/floods and the college football papers were robust to the inclusion of out-of-sample observations, but the former was not robust to the inclusion of theoretically motivated unit fixed effects. The tornado paper’s main result was sensitive to a particular coding of a variable that departed from how it was described in the original article, and in no case did we find support for the originally reported heterogeneous treatment effects. This indicates that the strength of the evidence for the electoral effects of irrelevant events is weaker than was originally reported, but also suggests that the binary concept of “replicated / did not replicate” are likely an oversimplification.
Though our analyses did not fully confirm or overturn the original findings of any individual study, we view this as a strength of our approach. Without the disciplining features of our approach, we could have easily “null hacked” away all of these studies with selective reporting. However, our approach required us to see the full, more complex story.
This blog piece is based on the article “Irrelevant Events and Voting Behavior: Replications Using Principles from Open Science” by Matthew H. Graham, Gregory A. Huber, Neil Malhotra and Cecilia Hyunjung Mo, forthcoming in the Journal of Politics.
The empirical analysis of this article has been successfully replicated by the JOP. Data and supporting materials necessary to reproduce the numerical results in the article are available in the JOP Dataverse.
About the authors
Matthew H. Graham is Postdoctoral Associate at the Institute for Data, Democracy, and Politics at George Washington University, School of Media and Public Affairs. You can find more information about his work here and follow him on Twitter: @Matt_Graham
Gregory A. Huber is the Forst Family Professor of Political Science at Yale University. You can find more information about his work here.
Neil Malhotra is the yEdith M. Cornell Professor of Political Economy at Stanford Graduate School of Business. You can find more information about his work here and follow him on Twitter: @namalhotra
Cecilia Hyunjung Mo is the Judith E. Gruber Associate Professor of Political Science and Public Policy at University of California, Berkeley. You can find more information on her research here and follow her on Twitter: @ceciliamo