We propose a method to estimate sub-national public opinion from national survey data. Our approach extends the current gold-standard, multilevel regression, and post-stratification (MrP), with standard machine learning techniques to improve prediction accuracy. We also provide a package for the R statistical computing environment that implements our approach. This package, called autoMrP, is available for download from CRAN and GitHub.
The Problem
A frequent problem that arises in various disciplines is that researchers have population-representative data and want to draw inferences for sub-populations from these data. This problem may be encountered by political scientists who wish to estimate sub-national (e.g., state-level) support for public policies based on national survey data or epidemiologists estimating state-level prevalence of health outcomes. Common to all such applications is that limited national data are being used to estimate outcomes at a lower level, such as the state level.
The MrP Model
One ‘solution’ that has been proposed to deal with the above problem is disaggregation, which means taking the average value of the outcome for each lower-level unit as the estimate. This approach performs badly for small units with few data and is generally not efficient when data are sparse. We can achieve better estimates by modeling the individual-level outcome as a function of individual-level variables and variables at higher levels in a multilevel model and then post-stratify these predictions (these models are called MrP models). Based on such a model researchers can create predictions for all demographic-geographic ideal types (e.g. 18-34 year old African-American man with a high school diploma living in California) and then weigh these predictions by the frequency of the ideal types within the sub-national units.
Since the introduction of the standard MrP approach, authors have suggested various ways of improving its prediction performance. Some proposed to include interactions of random effects to provide the model with more flexibility, which in turn provides more precise estimates for different ideal types. Others showed that if there are many sub-national units, such as in the case of legislative elections in Germany, spatially correlated random effects can be included to improve the estimates. But, one area has not been addressed for a long time. How should researchers specify their models ideally?
The Contribution of Machine Learning
In our JOP research note, we start by recognizing that MrP is a prediction model. The individual level of an MrP model includes only random effects, which are by definition shrunk towards the grand mean. They, therefore, provide (some) protection against overfitting. The contextual level commonly consists of two parts: a systematic part and the random effect for subnational units. The risk of overfitting comes from the systematic part since it contains fixed parameters with no regularization. Disregarding context-level information entirely by omitting the systematic part might lead to underfitting since geographical variation can now only result from the subnational-units random effect. The extent to which variation at the context level is underestimated is partly driven by subnational sample sizes, with smaller samples leading to more shrinkage of the random effect. Both overfitting and underfitting diminish the prediction accuracy of the model. Hence, the question is how to best specify a model that increases prediction accuracy. We focus on context-level features for three reasons. First, as mentioned above, shrinkage at the individual level already provides protection against overfitting. Second, context-level variables have been shown to provide larger improvements in model performance compared to variables at the individual. Third, the risk of overfitting at the context-level is typically larger due to the low number of subnational units.
Our approach, autoMrP, relies on five classification methods to model individual response behavior and combines them via ensemble Bayesian model averaging. Note that our approach is fully flexible, allowing scholars to easily extend the set of classifiers by adding additional models. The classifiers we use are (i) multilevel regression with best subset selection of context-level predictors (Best Subset), (ii) multilevel regression with best subset selection of principal components of context-level predictors (PCA), (iii) multilevel regression with L1 regularization (Lasso), (iv) gradient boosting (GB), and (v) support vector machine (SVM). We combine the predictions of the individual classifiers by relying on ensemble Bayesian model averaging (EBMA). The weights that determine each classifiers’ contribution to the overall prediction depend on the classifiers’ performance on new (i.e., previously unseen) data.
We are not the first to recognize that insights from machine learning can be fruitfully combined with the more classical approach of MrP. Ornstein proposes an approach that is similar to ours but uses a slightly different set of classifiers and an alternative approach to build an ensemble prediction (stacking). Bisbee modifies MrP by replacing the multilevel model with Bayesian additive regression trees (BARP), leading to improvements in prediction performance.
To assess the predictive quality of various classifiers we rely on the canonical dataset used by Buttice and Highton. This allows us to explore how well the methods proposed by Ornstein and Bisbee perform and we can compare their performance to the one of autoMrP. Figure 1 shows that systematic approaches relying on machine learning can improve upon the baseline model. In addition, we see that autoMrP outperforms the other two alternatives in this comparison based on the Buttice and Highton data.
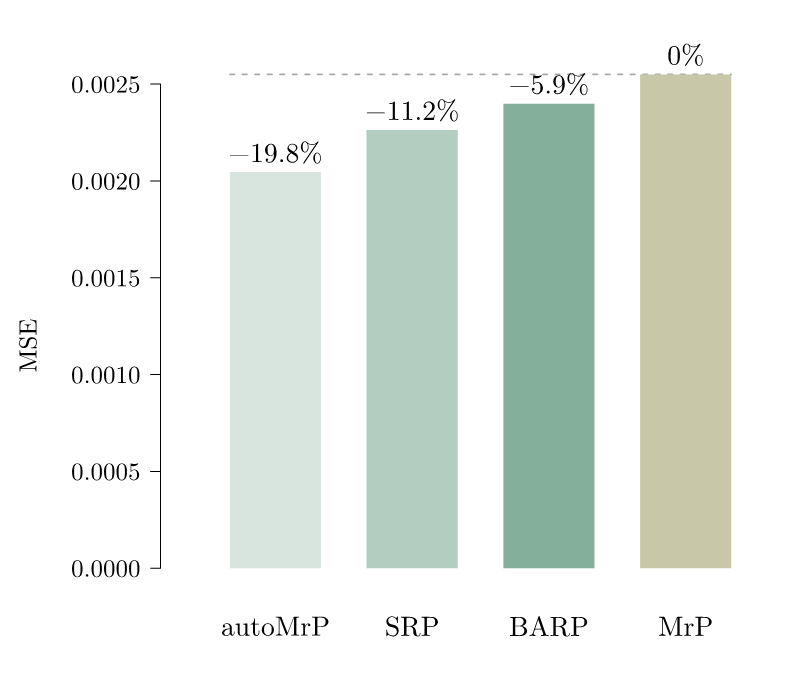
Note: Average MSE of state-level predictions over 89 survey items. MrP is the standard MrP model with all context-level variables. SRP is the Ornstein (2020a) package and BARP is the Bisbee (2020) package. Percentage numbers: Comparison to standard MrP model.
Readers interested in using autoMrP can download the R package autoMrP from CRAN and directly apply the ensemble estimator or just rely on individual classifiers. The package also provides an approximation of the estimates’ uncertainty. In addition, the package can also be used to estimate a regular MrP model. The package’s vignette provides a number of possible applications and illustrations.